Singularity is a narrow band
On this page

(ノ´ヮ´)ノ*:・゚✧
Earlier this month, a research paper I co-wrote with Ninon Devis Salvy for the CNC Lab was published. 30+ pages, in French, academic register. Not expecting many people to actually read it... so!, this post stands as a tldr.
The CNC Lab is the R&D branch of the Centre national du cinéma et de l'image animée, France's public agency for film and moving images. They put out a call for contributions last year on two themes: AI and creation, and children's relationship to image consumption. We answered the first one.
Our paper ("Singularity and Creation in the Age of AI") runs at a single question: where does originality live when the model producing it averages everything it has seen? Philosophy has its angles: intuition under algorithms, the algorithmic image, art past aesthetics. We took the empirical route: two experiments, one on text and one on images.
How do you push generative AI past the average?
Generative models (the ones behind ChatGPT or Stable Diffusion) are trained on huge piles of existing content. By default, they produce the statistical average of that pile. Text that reads like text. Images that look like images. Nothing wrong with that for summarizing documents, answering questions, or analyzing data, where reproducibility is what you want. For more creative use cases though, this becomes a ceiling. So how do you push past it without tipping the model into incoherent noise?
How hot can language get before it breaks?
Every language model has a parameter called temperature. Low temperature means the model plays it safe and picks the most likely next word. The output looks smooth and predictable. High temperature means the model gets bolder and picks less likely words. The output gets weirder. At extreme temperature, it stops making sense and becomes pure gibberish.
GPT-4.1 exposes temperature from 0 to 2. We swept the full range in 0.1 steps across three different prompts/input queries (a synopsis, a dialogue, a storyboard description). Ten outputs per setting. For each one we measured three things:
- linguistic integrity (is the output still valid language?),
- lexical diversity (how varied is the vocabulary?),
- semantic alignment (how close does the output stay to the prompt's meaning?).
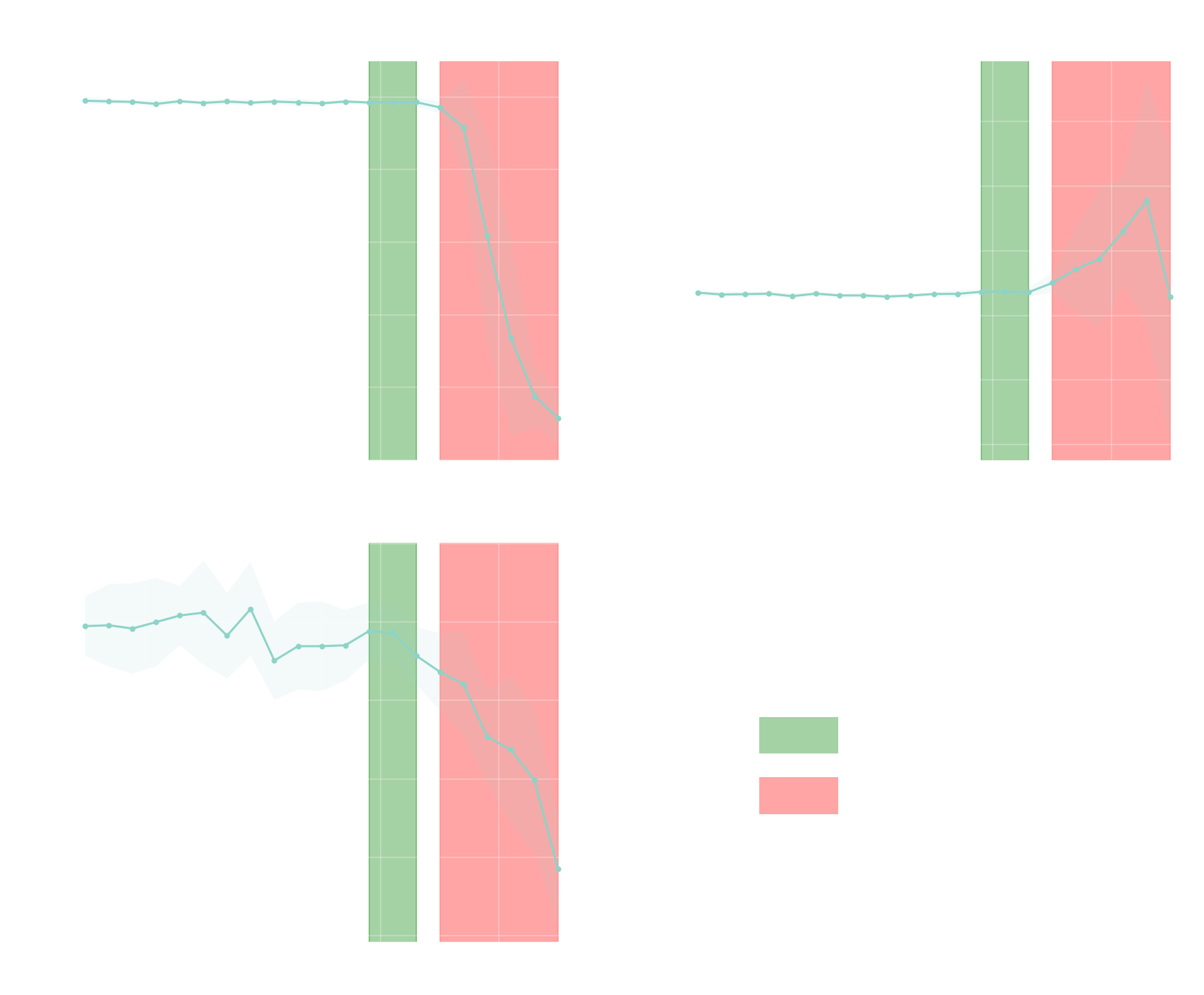
Three regimes came out. Below 1.2 is the plateau regime, where outputs are coherent but predictable. Most of the variation the model can produce is unexploited. Between 1.2 and 1.4 is the singularity zone: outputs diverge from the default while staying readable. That's the zone worth experimenting with if you're using the model for anything creative. From 1.5 onward, the model derails: mixed languages, invented tokens, semantic drift. Past that we enter the rupture regime, where outputs are barely usable unless weirdness is the point. To give you an idea, here are three outputs from the same opening line (translated from French):
Input query: "In the Year 2125, three-quarters of the world's population have lost their sight due to…"
T = 0.0
…a swift pandemic, dubbed "the White Shadow", which spread in less than six months. Scientists were never able to determine whether its origin was natural or the product of human manipulation. The first symptoms were mild: slight eye discomfort, halos of light, then, suddenly, total blindness.
T = 1.4
…a luminous wave of unknown origin that struck the planet during the "Great Opal Flash". Within minutes, humanity was plunged into permanent darkness. Faced with this new era, everything had to be rethought: cities adapted, infrastructure was reinvented to operate without visual cues, and human exchanges evolved toward new sensory modes.
T = 2.0
…a mutation encoded by the famous "Copper Genome", spread through the atmosphere after the地astra-halopoly(headstormkrift الم produjo koll gebeur acabadou oft pegasesabay暨린어 জল Prathanator supera which myster выращ bevorzug럼 coronFillLTERstenen giàiiedades desenvol виде největ Mutó điều: Wochenendesoil…
The singularity zone is narrow and sits immediately before the rupture. It's surprisingly specific. Its exact location depends on the model. Our experiments focused on GPT-4.1. Other models have their own zone.
Newer models (like GPT-5) don't even expose the dial anymore. Every hidden dial is one less lever to push the model past its defaults.
What generalizes is not the values but the shape: a narrow band before the rupture.
Images and the Pareto frontier
For images the question is the same but the controls are different. With Stable Diffusion 1.5 we generated several thousand images from the same sci-fi opening line as above. We varied three kinds of dials:
- guidance scale (how strictly the model sticks to the prompt),
- latent noise injection (how much random noise we inject during generation),
- controlled semantic drift (how much weight we put on specific stylistic keywords).
Then for each image we asked two things. Does it actually illustrate the brief, or would it fit any prompt? Does it look different from the default the model wants to give you? These two goals work against each other. Stick close to the prompt and the image looks average. Push for something different and it drifts off the prompt. The interesting images are the ones that do both. There's only a narrow zone where that's possible. In optimization theory, that shape is called a Pareto frontier. Again, here are snippets from our experiments:
Baseline: what the model produces when you don't push it. Literal, competent, expected, redundant over iterations.





Chaos: what "crank divergence to the max" actually produces. An image in the sense that it has pixels. Pure noise.

Sweet spot: the middle ground between the default and chaos. Evoked, not illustrated.




The baseline illustrates the prompt. Chaos is unusable. The sweet spot sits between these two regimes. It's a choice. You only reach it by accepting that there isn't a single setting that produces "good". The Pareto frontier is a set of trade-offs between specificity and singularity. The work is deciding which trade-off to make.
NB: one honest limit. The frontier is measured, but the labels (baseline, chaos, sweet spot) are aesthetic calls. LPIPS, the metric we use, captures how different two images look, not whether they're good. To judge composition, emotional impact, or fine-grained narrative coherence, we would have needed to run a qualitative human study.
What artists working with AI actually do
Both experiments converge on the same finding, which we call controlled divergence. The point here is that singularity in AI creation lives in a narrow band where the model diverges from its statistical center without losing coherence. The band is small. Push too gently and the output stays average. Push too hard and it collapses into noise.
This changes what the artist is doing. They're not writing the prompt and then picking their favorite of four outputs. They're shaping the parameter space from which outputs emerge: which dials, at what range, with which constraints, seeded how. The final image or paragraph is downstream of that shaping. In the paper we call this being an architect of generative conditions rather than an author of generated results.
This shift takes different shapes across the field. Jennifer Walshe puts it this way: "the gap between what is described and what is produced, between intent and result, is now the domain of the network." For Grégory Chatonsky, the latent space itself is "the new domain of technical imagination." Beth Coleman calls for "a generatively wild AI that exceeds the framework of predictive machine learning," not the reproductive default. Authorship has moved upstream of the output.
Against frictionless iteration
Which brings me to the part of the paper I'm most attached to. If the zone is that narrow, you don't land in it by infinite iterations. You have to commit.
When iterating is free, every choice becomes trivial. If I can regenerate this image at zero cost, my decision to keep it is barely a decision. And a workflow made of barely-decisions produces work that feels like nobody made it.
The paper's proposal against this is what we call methodical friction. Deliberately constrain the loop. Fixed iteration budgets. Locked seeds. Irreversible choices. Rules you actually have to live with. The counterintuitive claim is that friction is what makes a gesture a gesture. Remove all of it and what's left is curation at best.
In January 2025, Ninon and I took part in Wilding AI, a research residency Beth Coleman co-leads in Berlin ahead of CTM Festival. The brief was to hack, misuse and break generative AI tools. A full week of practicing friction and getting as far as possible from frictionlessness.
Surely this is not specific to AI creation. It's a useful rule for any creative process where the marginal cost of trying one more thing has collapsed. But it's especially urgent here, because the industry's whole direction of travel is toward more frictionless design. Cheaper, faster, fewer parameters, more automation. If that's all there is, we end up with interchangeable options and no authorship. "If the point is to imitate human work at cheap cost, that's dull. If it is to explore new forms, that's when it gets interesting."
A gesture only counts when trying a different one would have cost you something.
Voilà! That's roughly the spine of the paper. You can download the full (french) version, or find it alongside other contributions from the same call on the CNC Lab website. Happy to talk about any of it.
Co-authored with my dear friend and collaborator Ninon Devis Salvy. Special thanks to Pollinations.AI for the GPU compute they provided us for our experiments.